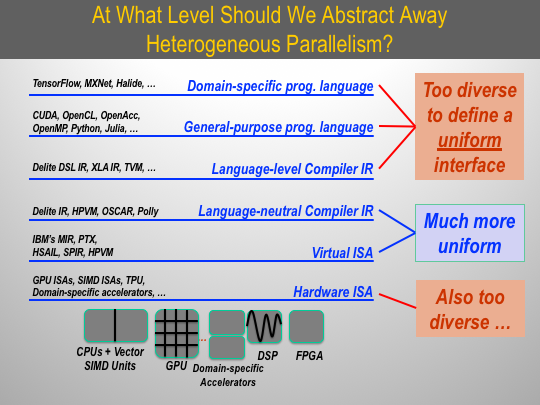
The goal of HPVM research project is to make heterogeneous systems easier to program. A key aspect of our strategy is to develop a uniform parallel program representation for heterogeneous systems that can capture a wide range of popular parallel hardware, including GPUs, vector instruction sets, multicore CPUs, FPGAs, and domain-specific accelerators. One question we must answer is: At what level of the hardware+software stack is it most effective to capture heterogeneous parallelism with a uniform interface? The figure below illustrates the major choices (layers of the stack) and why we believe that the two best options are in a language-neutral compiler intermediate representation (IR) and in a virtual instruction set (ISA).
The representation we have developed is called HPVM (Heterogeneous Parallel Virtual Machine): a hierarchical dataflow graph with shared memory and vector instructions. It supports three important capabilities for programming heterogeneous systems: a language-neutral and hardware-neutral compiler IR, a virtual ISA, and a basis for runtime scheduling; previous systems focus on only one of these capabilities. As a compiler IR, HPVM aims to enable effective code generation and optimization for heterogeneous systems. As a virtual ISA, it aims to achieve both functional portability and performance portability cross such systems. At runtime, HPVM enables flexible scheduling policies, both through the graph structure and the ability to compile individual nodes in a program to any of the target devices on a system. We have implemented a prototype system, with a compiler IR supporting optimizations directly on the graph IR; a virtual ISA that can be used to ship executable programs; code generators that translate HPVM program nodes to nVidia GPUs, Intel’s AVX vector units, and to multicore X86 processors. Experimental results show that HPVM optimizations achieve significant performance improvements, HPVM translators achieve performance competitive with manually developed OpenCL code for both GPUs and vector hardware, and that runtime scheduling policies can make use of both program and runtime information to exploit the flexible compilation capabilities.